

Hogy rögtön a tárgyra térjünk: vagy nagyjából 60 millió dollárért kiszervezzük a munkát fillérekért egy „fejlődő országba”, és várunk pár hónapot, vagy megkérünk szépen egymillió embert, hogy csinálja meg az egészet 80 óra alatt ingyen. Igen, a kedves olvasót is. És mindenki szépen csinálja is, anélkül, hogy tudna róla.
Elsőre ez bizony akkora összeesküvés-elméletnek hangzik, mint a lapos-Föld vagy a gyíkemberek, azzal az apró különbséggel, hogy ez bizony az utolsó betűjéig igaz. Jó, tudjuk, a laposföldesek is ezt mondják, de hadd meséljük el a sztorit az összes bizonyítékával együtt. Zseniális lesz.
Először ugorjunk egy picit vissza az időben, nagyjából a 2000-es évek elejére, amikor Luis von Ahn, egy egészen elképesztően zseniális matematikus rájött, hogy ötlete, a CAPTCHA ugyan megnöveli az interneten történő adatok bevitelének a biztonságát, ugyanakkor emberek százmillióinak életét keseríti meg. De mi is a CAPTCHA? Biztosan mindenki találkozott már vele: gyakorlatilag az a furcsa, torz karaktersor, vagy gyors művelet, amit annak idején mindenhova be kellett írnunk, miután megadtuk az adatainkat, és bizonyítani kellett, hogy mi valódi emberként végezzük ezt az adatbevitelt.
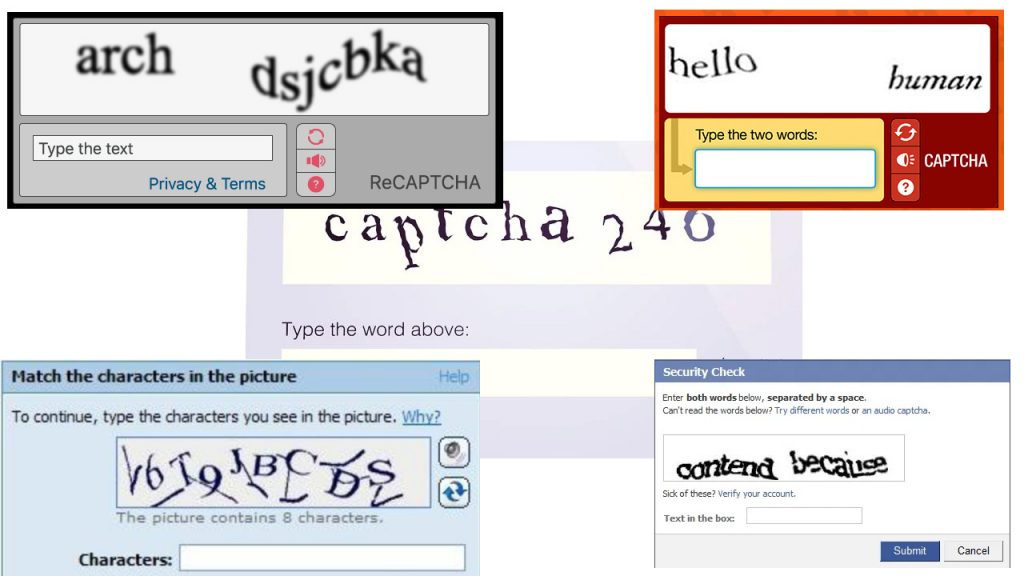
A módszer fontos és hasznos volt, hiszen így lehetett elkerülni, hogy egyszerű algoritmusok jelentkezzenek be a nevünkben különféle szolgáltatásokba, hogy aztán a nevünkben műveljenek mindenféle helytelen dolgot a spameléstől a kéretlen hirdetéseken át a konkrét csalásokig.
A CAPTCHA módszere persze folyamatosan fejlődött: ma már az olvashatatlan betű- és számkombinációk helyett inkább be kell jelölnünk a tűzcsapokat vagy zebrákat vagy buszokat vagy bármilyen más elemet a kis képkockákon, mielőtt a “Regisztrálok” vagy az “OK” gombra kattintunk. Ez megint csak olyasmi, amit egy gép (jó esetben) nem tud megtenni a nevünkben.
Annak idején minden egyes ilyen képrejtvény bevitele átlagosan 10 másodpercet vett el a felhasználók életéből. Mivel pedig rengeteg weboldalon emberek tízmilliói használták, ezért egyetlen nap alatt összesen 500 000 órányi értékes idő veszett el az emberiség életéből – igen, ötszázezer óra naponta, nem elírás. És itt bukkant fel egy érdekes gondolat: milyen jó lenne, ha ezt a rengeteg felesleges időt valami hasznos és igazán fontos dologra lehetne felhasználni, miközben nem engedünk az adatbevitel biztonságából sem, vagyis megmaradna CAPTCHA alapvető biztonsági funkciója is?
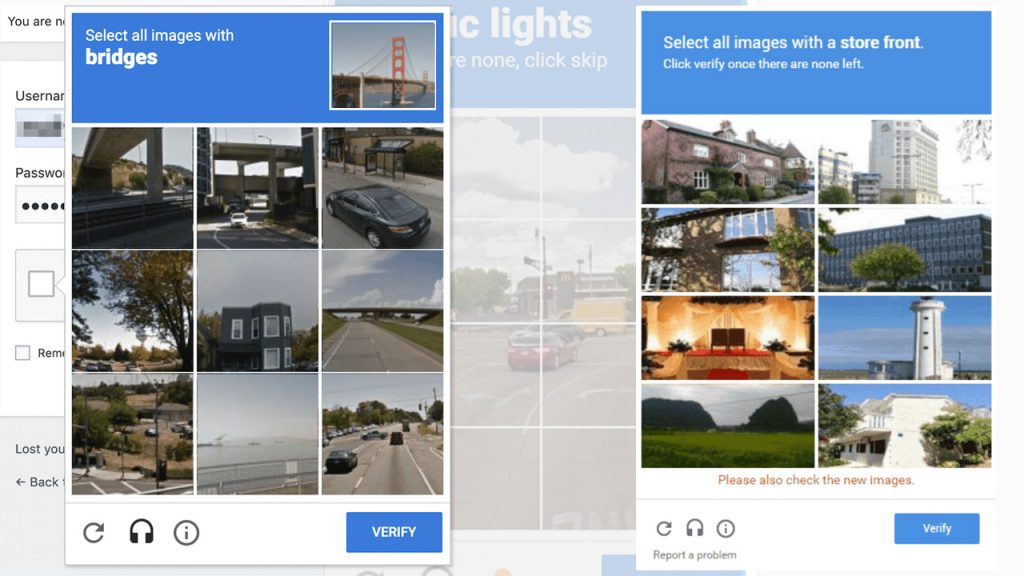
Így született meg 2007-ben Luis és csapata által a továbbfejlesztett reCAPTCHA, amit már tényleg mindenki ismer, aki az elmúlt pár évben, bárhol, bármilyen adatot megadott a neten. A reCAPTCHA az, amikor két furcsán eltorzított és sokszor értelmetlen szót látunk és mind a kettőt be kell gépelni ahhoz, hogy bebizonyítsuk nem vagyunk robotok.
Mik ezek a furcsa szavak? Honnan jönnek és hogyan ellenőrzi a rendszer, hogy tényleg nem vagyok robotok? Ez az, ami elképesztően zseniális ebben az egészben: amellett ugyanis, hogy saját webes belépéseink extra biztonsági lépéseként használtuk ezt a módszert, gyakorlatilag minden egyes szó begépelésével segítettünk bedigitalizálni a világ könyveit. A kétezres évek elején ugyanis sok cég kezdett azzal foglalkozni – többek között a Google és az Amazon is, de jó néhány egyetemen is előkerült ez a projekt – hogy beszkennelje a világ könyvtáraiban megtalálható könyveket és dokumentumokat, hogy aztán digitális formátumban őrizzék meg őket az utókornak.
Igen ám, de a 30-40-50 éves könyvekben, az elsárgult papíron, az elfolyt festékkel írott betűkkel nagyon sokszor nem birkózott meg a technika. Hiába létezett már akkor is az OCR (optikai karakterfelismerés) technológiája, a számítógép rengeteget hibázott, és egész egyszerűen volt nagyon sok szó, kifejezés és mondat, amit nem tudod beolvasni. Úgyhogy Luis kitalálta, hogy mi lenne, ha azt a napi fél millió órát a weben ide-oda belépkedő, valódi hús-vér emberekre bíznánk. Ez lett a reCAPTCHA: azok a furcsa eltorzult dupla szavak, amiket annak idején begépeltünk, bizony minden egyes alkalommal a fent említett, nehezen olvasható könyv-lapokról készült apró képdarabkák voltak, amiket nem ismert fel a rendszer. Ebben az esetben, míg az egyik szóról pontosan tudta a rendszer, hogy mit jelent és hogyan kell beírni – ezzel igazolni magunkat, hiszen el tudjuk olvasni – addig a másik szóról fogalma sem volt, mit jelent. De mivel az ismeretlen karaktereket a gép “odaadta” több ezer felhasználónak is, így a legtöbb találatot kapott “megoldás” bekerült a beszkennelt könyv digitális verziójába és jöhetett a következő ismeretlen kifejezés.

Az, hogy Luis és csapata díjakat nyert és az egész világ elismerte zsenialitását, már önmagában is hatalmas siker, de 2009-ben szőröstül-bőröstül megvette az egész projektet a Google, hogy még jobban kiterjessze a projektet és még tovább használja a mi szemünket ahhoz, amire a számítógépes karakterfelismerés és kamerák nem voltak képesek. Más talán hátradőlt volna a Google-lel a háta mögött és boldogan kávézgatott volna a karosszékben, hogy milyen komoly dolgot tett le az asztalra, Luis azonban ennél is tovább gondolkodott. Úgy vélte, az odáig nagyszerű, hogy most már könyvek millióit digitalizáljuk be, de olyan jó lenne, ha ezeket a könyveket (és nem mellékesen akár a teljes internetet) lefordítanánk, hogy ne legyenek egyáltalán nyelvi korlátok.
Vegyük például a címben szereplő Wikipédiát. A kétezres évek közepén a spanyol nyelvű Wikipédia mindössze a húsz százalékát tette ki terjedelemben az angol nyelven elérhető változatnak. Mennyi időbe, pénzbe és energiába kerül lefordítani a maradék 80 százaléknyi angol szöveget spanyolra, hogy a világ egyik legtöbbet beszélt nyelvén is megjelenhessen minden Wikipédia szócikk az angol eredetiből? Ha hivatalos fordítói díjakat és egyéb költségeket számolunk, ez az a mai értéken 60 millió dollár, amit a cikk elején is említettünk, ám ez kivitelezhetetlen tette a projektet. Luis azonban arra gondolt, hogy ha már egyszer bejött ez a közösségi munka, akkor valamilyen úton-módon talán rá lehetne venni a felhasználókat, hogy most szkennelés és szófelismerés helyett átálljanak a fordításra.
Igen ám, de míg a reCAPTCHA egy kikerülhetetlen és kötelező biztonsági feladat volt, azért a fordítás már más tészta. Több időt igényel, nagyobb odafigyeléssel jár, így nem olyan egyszerű rávenni a netezőket, hogy csak úgy ajándékba adják az idejüket. A trükkös feltaláló azonban rájött, hogy több mint egymilliárd ember tanul nyelvet a bolygón, tehát ha a nyelvtanulás iránt érdeklődőket rá tudná venni valahogy arra, hogy miközben nyelvet tanulnak egyúttal valós szöveget fordítsanak le kifejezésenként, rövid mondatonként haladva, az nagymértékben előrelendítheti a komplett digitalizációs projektet. Ezzel két legyet üthetünk egy csapásra, hiszen míg az egyik oldalon nagyon olcsón, sőt akár ingyen – és ez egy fontos szempont volt a projektben – nyelvet tanul valaki, addig a másik oldalon olyan, a való világból, létező könyvekből és dokumentumokból származó szövegeket kapjanak a felhasználók, amiket aztán spanyolra, japánra, németre, franciára tudunk fordítani a segítségükkel, és így akár el tudnak készülni az említett Wikipédia szócikkek is.
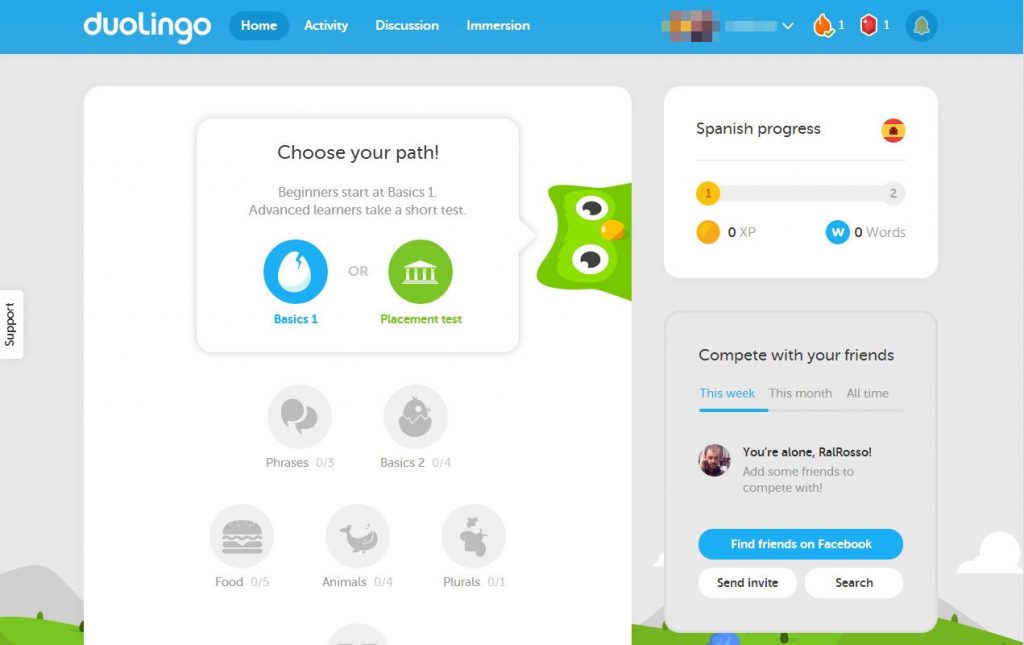
Ez aztán egy olyan projektté nőtte ki magát, ami ma már olyan vizsgát ad, amit például az USA bevándorlási hivatala elfogad hivatalos angol nyelvvizsgaként: ez nem más, mint a Duolingo nyelvtanuló platform, a Google által szponzorált applikáció és weboldal, amin keresztül sok millió felhasználó, miközben különböző nyelvet tanul, „mellesleg” azokat a könyveket, weboldalakat és szócikkeket fordítja le, amiket máskülönben nem érnének el azok, akik nem beszélnek angolul.
Most, hogy elértünk a végére, nyugodtan megpaskolhatjuk a saját vállunkat, hiszen a kedves olvasó és mi magunk is, ha csak egy morzsányit is, de részt vettünk ebben a közös munkában, hogy egy új kollektív és nyelvi korlátok nélküli közös tudást hozzunk létre az interneten. Persze azért kellett hozzá Luis és a csapata is… Talán egyedül a fordítóirodák nem örülnek annak, hogy az eredetileg nekik szánt munkát elvégezte az egész világ egy fillér ráfordítása nélkül. Hol tart már a tudomány…








{kind=link}