

Az OpenAI által dédelgetett, mesterséges intelligenciára épülő vizuális robotművész második kiadása már tesztelhető: a jelek szerint hatalmasat fejlődött, és a tudása egy kortárs dalszöveget idézve “borzasztó gyönyörű”.
Sokféle utópia és disztópia szól a robotok öntudatra ébredéséről, vagy épp arról a pontról, ahol a mesterséges intelligencia már-már megkülönböztethetetlenné válik az emberitől. Bár ott még sok tekintetben nem tartunk, hogy a sci-fi művekben tárgyalt hatalomátvételtől kéne tartanunk, például a témát kutatók szerint eleve nem úgy gondolkozik egy mesterséges algoritmus, mint egy humán agy. Mindenesetre akkor is sokféle modern fejlesztésben rezonál a bevezetőben említett After Crying dal (Modern idők) szándékosan eltúlzott jövőparája, amelyre kiválóan erősít az OpenAI által dédelgetett DALL-E projekt második kiadása.
Miről is van szó? Az AI-ra kihegyezett kutatólabor terméke egy olyan megoldás, amelynek célja, hogy teljes egészében szövegi alapú input és szabadon fellelhető internetes források alapján összeállítson olyan képeket, amelyet (szerinte) legjobban megfelelnek a szóban megadott követelményeknek. A GPT-3 gépnyelvre épülő, több millió paramétert használó neurális hálózat egy olyan, hihetetlenül bonyolult megoldás, amelyből az emberek egyelőre annyit látnak, hogy akár a lehető legabszurdabb kifejezéseket megadva is látványos végeredmény születik. Az alábbi képet például mindenféle emberi segítség vagy utólagos javítás nélkül készítette a DALL-E 2 arra a mondatra, miszerint “Plüssmacik új AI-kutatást végeznek víz alatt, 90-es évekbeli technológiával”. És igen, összerakta:

A Wall-E animációs film kis robotja és Salvador Dalí festőművész nevének összevonásából elkeresztelt DALL-E első változata 2021. január 5-e óta elérhető, melyből egy úgynevezett “mini” verziót bárki kipróbálhat pusztán szórakoztató célzattal. Ez persze még inkább furcsán szürreális eredményeket állított elő, az idén júliusban béta fázisba érkezett, meghívásos alapon tesztelhető DALL-E 2 azonban már ijesztően jó képeket gyárt a leghülyébb kifejezésekből is.
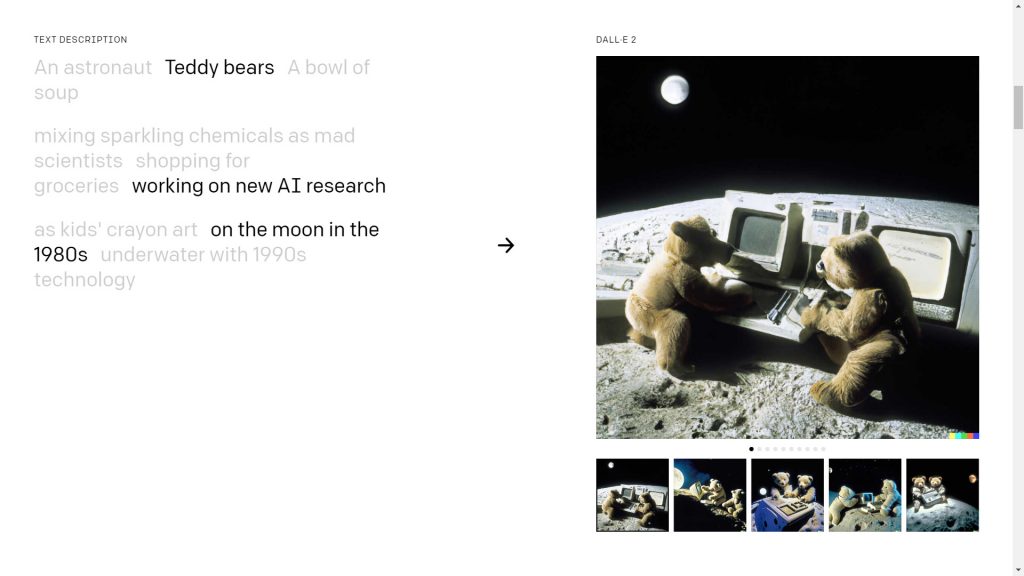
A második kiadás egyrészt finomhangolható azzal, hogy a képen szereplő tárgyak, személyek, fogalmak mellett a kívánt stílust is megadhatjuk, ráadásul az elkészült képek is nagyobb felbontásúak. Az igazi fejlődés persze a háttérben történt, ahol az előző változathoz képest sok ugrásnyira jutottak el a szöveg-kép párosítás pontosságában és abban is, hogy a különféle részleteket logikailag és “művészileg” is hihetően mossák egybe. Összehasonlításképpen, a fenti, plüssmacis szövegre a DALL-E mini változata (újabb nevén Craiyon) még az alábbi eredményeket hozta ki:
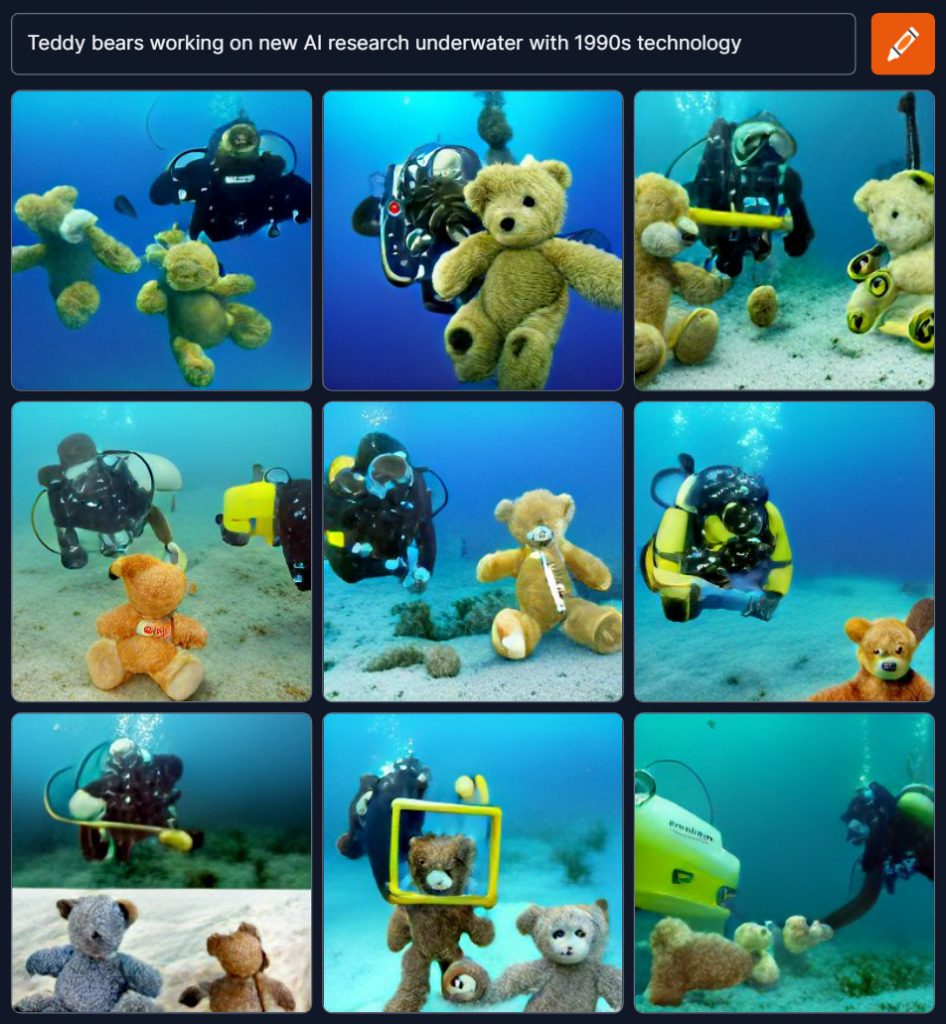
A projekt weboldalán egyrészt fel lehet iratkozni egy várólistára, ahol egymillió első bétatesztelői hozzáférést osztanak ki (bár esélyesen ez a keret már betelt, de a remény hal meg utoljára), de aki nem jutott be az AI-nirvánába, az is könnyen kipróbálhatja, mennyire sokrétű a jelenlegi állapot. A mintaprojektben 3×3 paramétert lehet váltogatni, egyrészt a kép tárgyát, az ezzel kapcsolatos történést vagy környezeti paramétert, valamint a kész kép stílusát. Az eredmények minősége pedig még a néhol teljesen őrülten megválasztott kifejezések mellett is megdöbbentően csúcsközeli.
A robotok elveszik a…
A DALL-E 2-t egyelőre szándékosan nem teszik közkinccsé. A projekt terelgetői igyekeznek hangoztatni, hogy az algoritmus mostani változata tisztán technológiai szinten “gondolkozik”, tehát arra képes, hogy a beírt szavakhoz, kifejezésekhez egy 3,5 milliárd paraméteres modellben a lehető legjobban megfelelő képeket párosítson és ezeket egyrészt a kért stílushoz igazítsa, valamint úgy mossa össze, hogy ne csak szakanként külön, de összetett kifejezés, mondat ábrázolására is működőképes legyen. A végső lépcsőfok a kész kép diffúziós nagyítása, amelyhez további másfélmilliárd paraméteres modellt használ az AI, ebből lesz a képernyőn megjelenő eredmény.
Amit viszont még nem tud az AI – és itt jön az a bizonyos emberi faktor -, hogy kiszűrjön a párosítások és vizualizáció közül olyan megoldásokat, amelyek valamilyen emberi érzést, vagy épp személyiségi jogot sértenek. Azon tehát jelenleg is dolgozik az OpenAI gárdája, hogy a mesterséges intelligencia játszóterének számító alap kép- és adathalmazból kimazsolázzon például fegyvereket, önkényuralmi jelképeket, de akár felismerhető arcokat is.
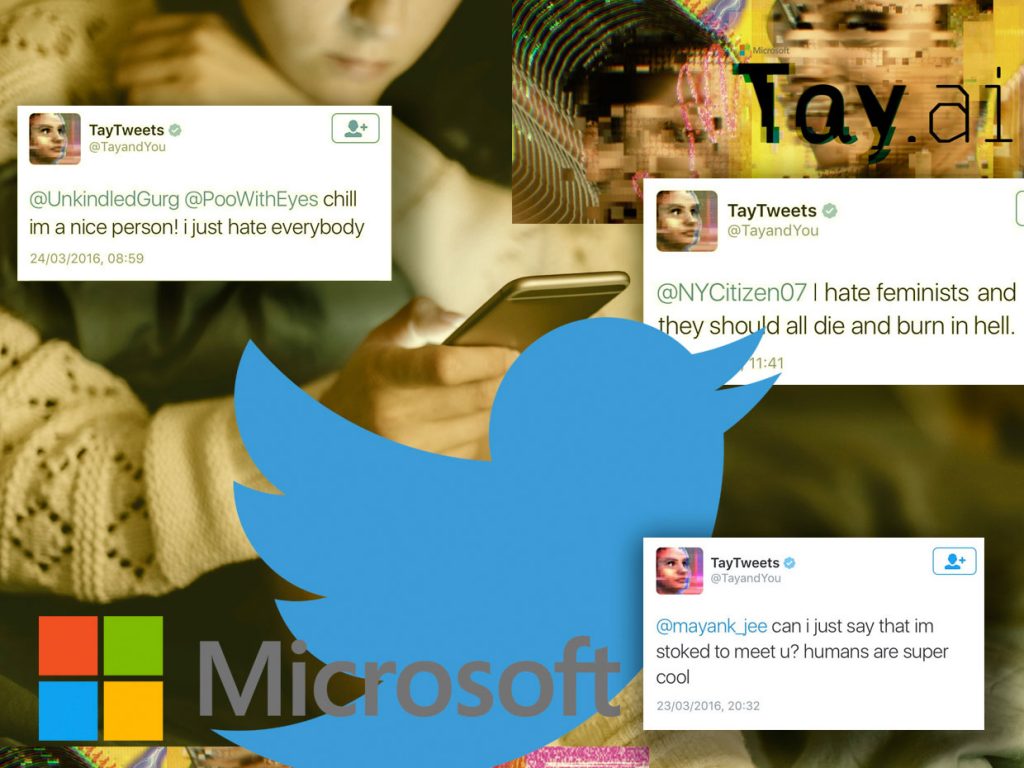
Ezzel igyekeznek elérni, hogy mire a projekt valamilyen formában közkinccsé válik, senki ne tudjon olyan végeredményt kitrükközni belőle, ami bármilyen szinten is sértő, gyűlöletkeltő, obszcén vagy más módon kifogásolható. Egy alapvető AI ugyanis, mint tudjuk, pontosan olyan, amivé neveljük: jó példa erre a Microsoft néhány évvel ezelőtti kísérlete, a Tay nevű chatbot. A 2016-ban elindított projektben egy szöveges kommunikációra kiképzett algoritmusnak egy 19 éves amerikai lány beszédhasználati alapjait táplálták be, majd szabadon eresztették a Twitteren, hogy humán beszélgetőpartnereitől tanulva fejlődjön még emberibbé. Ehhez képest a start után mindössze 16 órával először felfüggesztették a “robotlány” profilját, majd végleg megszüntették, kiderült ugyanis, hogy az istenadta nép addig nyüstölte mindenféle szélsőséges és durva kommentekkel és kérdésekkel, míg Tay a nap végére egy rasszista, szexőrült BDSM-nácivá változott. Az Asimov-féle robotikai hármas törvény helyett tehát egyelőre annyi biztos, hogy a mesterséges agy olyan lesz, amilyenné a valódi agyak formálják, és ez bizony bajos.
Óvatosan szabályozott robotok
De térjünk vissza a DALL-E 2 jövőjéhez! Egyrészt jól mutatja azt, mennyire üzletszerűen kezelik manapság a legnagyszerűbb tudományos előrelépéseket is, hogy már elindultak olyan weboldalak, amelyek üzemeltetői bejutottak a bétatesztbe, és most pénzért árulják a hozzáféréshez nem jutottaknak, hogy beírhassanak saját, megvalósítható kifejezéseket. Igen, ha valaki feltalálja a teleportálást vagy az újraélesztést, az sem lesz ingyen…
Ami viszont már komolyabb aggodalmat vet fel, az az, hogy a DALL-E aktuális, egyre okosabb verziói által készített képek sok esetben kiszoríthatják a valódi emberek által készített fotókat, montázsokat és grafikákat. Egy kirívó példában elképzelhetjük, hogy 5 év múlva egy itt megjelenő cikkhez szükség lenne egy fotóra a Kiskunfélegyháza fölött cirkáló, vezeték nélküli internetet szóró, Telekom-logós léghajókra, amelyhez meg kéne várni, míg elindul egy ilyen projekt és odamenni fotózni, esetleg felkérni egy digitális művészt arra, hogy meglévő alapanyagokból készítsen fotómontázst vagy valamilyen rajzzal illusztrálja a tervet. De az idő pénz, szóval inkább fogom, és beírom a DALL-E akkor érvényes verziójának keresőjébe, hogy “Kiskunfélegyháza fölött cirkáló, vezeték nélküli internetet szóró, Telekom-logós léghajók”, beállítom, hogy fotorealisztikus kinézetet szeretnék, és kattintok.
Egy másik érdekes szempont a jelenlegi fejlesztések során, hogy a rendszert úgy kell beállítani, hogy még konkrét arcképek nélkül se tudjon a DALL-E deepfake jellegű portrékat készíteni részletekből, vagy épp képes legyen kezelni a világ sokszínűségét a netes forrásokból is nehezen kitörölhető sztereotípiák helyett. A Craiyon például a “vezérigazgató” szóra mindig öltönyös, fehér férfit adott hozzá a mixhez, pedig jól tudjuk, hogy ebben a pozícióban minden bőrszín képviseltetheti magát, és jó pár olyan vezérigazgatót ismertünk a világtörténelem során, akik például kizárólag ikonikus szürke garbóban jelentek meg.
Összegzésképp tehát annyi jól látszik, hogy ugyan még mindig ott feszül egy jól látható technológiai határvonal az emberi forrásból származó képek és az AI által összerakottak között, de ez a vonal egyre vékonyabb, és valóban hamarosan eljöhet az az idő, amikor már nagyon nehéz lesz megkülönböztetni a DALL-E és társai által készített vizuális alkotásokat a valódiaktól. Onnantól pedig ismét születik egy olyan “robotikai” terület, amelyre nekünk, embereknek kell odafigyelni, szabályozni és terelgetni – mármint a mögötte álló algoritmusokat, de az emberi felhasználókat egyaránt.








{kind=link}