

A szuperszámítógépek fogalmát a nyilvánosság korábban inkább tudományos célokkal, kutatóintézetekkel kapcsoltak össze – pedig ma már egyre több nagyvállalat is épít magának. De mi is a szuperszámítógép tulajdonképpen, és miért jó, ha valakinek van sajátja?
Szupererő, szuperhold, Superman – a „szuper” jelzővel könnyen dobálózik a popkultúra, de a szuperszámítógépek esetében teljesen jogos a megkülönböztető jelző. Az ilyen óriásgépeket ugyanis nem csak úgy kell elképzelni, hogy egy otthoni PC-nél, esetleg egy vállalati szervernél kissé erősebb eszközről van szó. Míg egy ma átlagosnak számító otthoni vagy irodai gépben egyetlen központi processzor (CPU) és ebben 1-16 mag, tehát egyéni feladatmegoldó egység dolgozik, egy szuperszámítógép magjainak száma akár ezrekben, sőt milliókban mérhető. Ezzel és a hasonlóan erős többi alkatrésszel ezek a gépek persze nem arra valók, hogy nagyon gyorsan fusson rajta a Doom vagy az Office. Gyakran sokszorosan megosztott erőforrásokkal olyan komplex problémákra keresik a megoldást, mint a koronavírus legjobb gyógymódja, globális pénzügyi folyamatok elemzése vagy űrkutatási adatok rendszerezése.
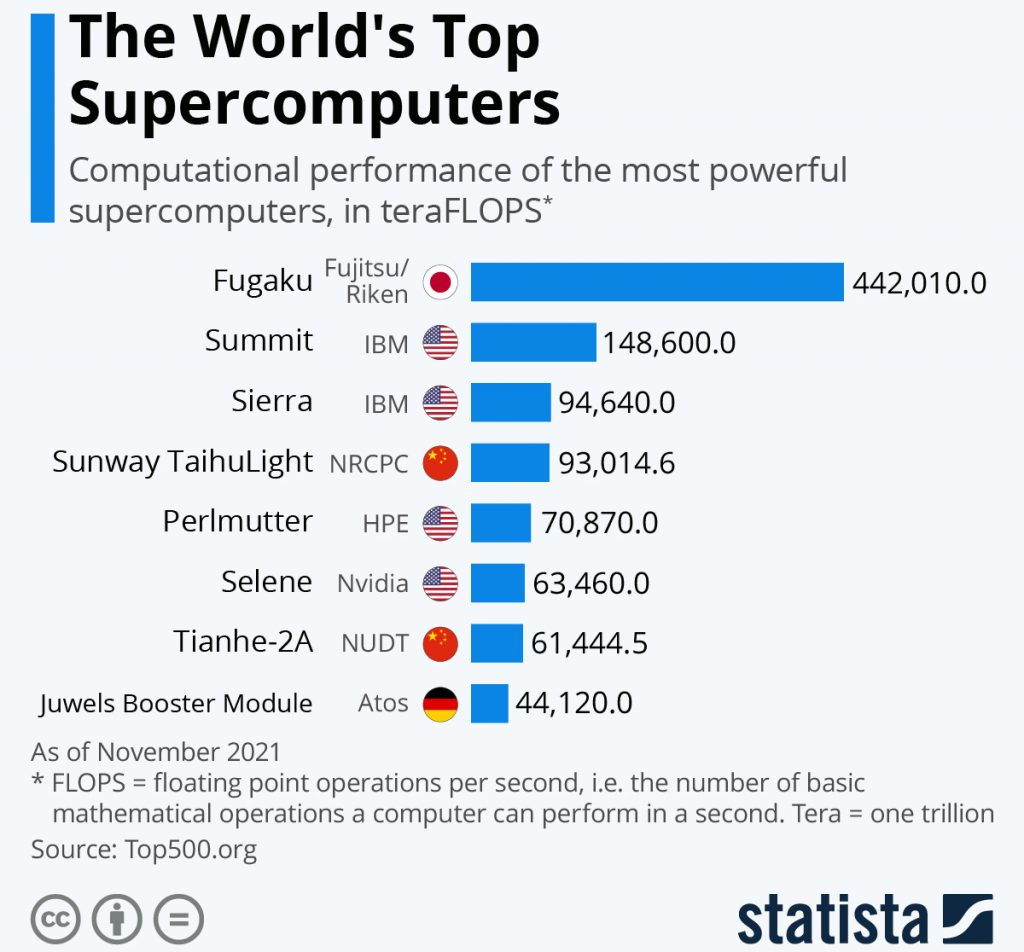
Ennek megfelelően az ilyen szupergépek felépítése és üzemeltetése sem épp olcsó feladat, a világ legnagyobbjai épp ezért nem is egy-egy vállalat kezében vannak, hanem kormányok és akár nemzetközi szervezetek segítségével, tudományos és oktatási intézményekben dolgoznak. A legnagyobbnak jelenleg a Japánban felépített Fugaku számít, amelyet a RIKEN Számítástechnikai Tudományos Intézet üzemeltet, ennek teljesítménye 442 010 TFLOPs. Na jó, máris magyarázzuk, mennyi ez. Az alap mértékegység itt a FLOPs, ami az egy másodperc alatt elvégzett lebegőpontos aritmetikai műveletek számát jelenti. Összehasonlításként egy iPhone 11 teljesítménye 736 GFLOPs, ahol a G a giga előtagot jelenti, ami a FLOPs 10 a kilencedik hatványra emelt értéke. A szuperszámítógépnél használt TFLOPs már tera- előtagot kapott, ez 10 a tizenkettedik hatványon. Nem megyünk bele mélyebben a matekba, a lényeg az, hogy a Fugaku teljesítménye annyi, mintha 600 000 iPhone 11 erejét adnánk össze.

Érthető, hogy egy ilyen óriásgépet már megépíteni sem kis feladat – sem műszakilag, sem pedig anyagilag, és a napi működtetése is irdatlan összegeket emészt fel. A Fujitsu által gyártott Fugaku értéke egybillió dollárra rúg, a monstrumban összesen 7 630 848 processzormag dolgozik, és laza 29 899 kilowatt energiát fogyaszt.
Az ilyen szupergépeket, mint már írtuk, nem is „egyben” használják: az üzemeltetőik általában az erőforrásaik egy-egy szeletét adják „bérbe” adott időtávra, illetve saját kutatási, elemzési projektekhez veszik igénybe. Legalábbis egy ideig ez volt a jellemző, de lassan változik a helyzet, egyes óriásvállalatok ugyanis úgy vélik, számukra saját céljaik eléréséhez is szuperszámítógépekre van szükség.
Teraflopok a metaverzumhoz
A nagyok nem szeretnek osztozkodni. A Google, a Facebook (illetve már egy ideje Meta), az Amazon, a Microsoft, az Apple és társaik értelemszerűen azt szeretnék, ha egy piac irányítása az ő és csakis az ő kezükben lenne. Míg ez a nézet tisztán üzletileg még érthető is lehetne, sajnos a dolog nem így működik. Mivel egyik cég sem lehet hivatalosan monopolhelyzetben (legalábbis, nyilvánvalóan, a hatóságok és szabályozók számára is láthatóan), ezért a piaci versenyben valamennyire kénytelenek a kegyeinkért küzdeni, így annyira nem tesz jót ezen vállalatoknak (sem), amikor rendre kiderül, hogy igazából mi felhasználók, puszta árucikkek vagyunk a számukra.
Szinte az összes nagy port kavaró botrány esetén rendre kiderült, hogy a jelszó-szivárgások, szerverfeltörések és egyéb fiaskók azért következtek be, mert a lehető legkevesebb erő- és pénz befektetésével akarták megszerezni és kezelni a lehető legtöbb felhasználói adatot. Az adatfeldolgozáshoz és azok minél gyorsabb kiértékeléshez pedig ma már nem elegendőek az említett cégek által eddig használt szerverparkok és adatközpontok, és láthatóan egyre többen igyekeznek a centralizált megoldások felé fordulni – már csak azért is, mert a jelen és közeljövő nagy tech-fejlesztései, a mesterséges intelligencia és a metaverzumok minden eddiginél hatalmasabb és összetettebb számítási hátteret igényelnek.
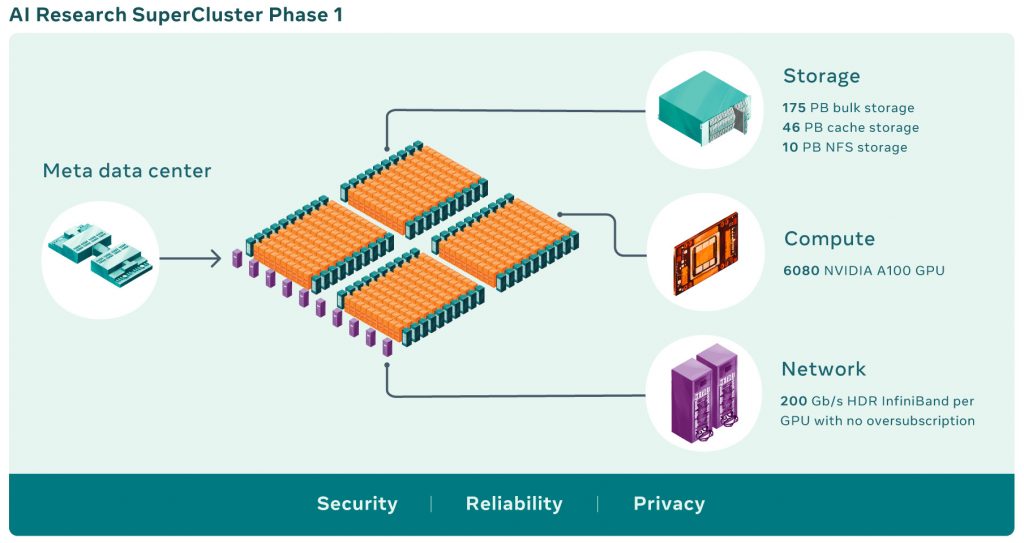
A Microsoft és az NVIDIA már rendelkezik szuperszámítógéppel: előbbi a redmondi cég Azure platformjának fejlesztését és üzemeltetését segíti, utóbbit pedig leginkább AI-kutatásokra szánták. Most pedig hivatalos a hír, hogy a Facebookból lett Meta is hadrendbe állítja idén a saját, kifejezetten AI megoldásokra szakosodott szuperszámítógépét, a Research SuperCluster-t. Az AI Research SuperCluster (röviden: RSC) ráadásul egy olyan számítógép, amit nem valamilyen „klasszikus” hardvergyártótól szereznek be, hanem a Meta mérnökei az alapoktól maguk tervezték. Az “előd-RSC”, vagyis hivatalosan az egyes fázis – ami már munkába állt – több, mint 6000 GPU-t tartalmaz – tehát nem annyira a CPU-ra, hanem a gépi tanulásra alkalmasabb grafikai processzorokra támaszkodik, és a Meta elmondása szerint már ez az első fázis is 20-szor nagyobb teljesítményre képes a “szabványos” szuperszámítógépeknél.
Azonban az idén elkészülő “kettes fázis” nem csak egy lapáttal tesz rá erre: az összesen nagyjából 16 000 GPU-jával képes lesz arra, hogy “több, mint egy billió paramétert tartalmazó AI-rendszereket tanítson, akár exabájtnyi, tehát egymilliárd gigabájtos szintű adathalmazokon”. Bár ez az összehasonlítás a többi szupergép teljesítményéhez mérve kissé sántít, mivel az AI területre specializált számítógépeknek nem kell olyan pontos számításokat végezniük a “normál” társaikhoz képest – ezért is tudnak gyorsabbak lenni -, azért nem kell szégyenkeznie majd az új RSC-nek sem.
A gépnek igen fontos szerepe lesz a Meta közeljövőjében, hiszen bizonyítania kell olyan területeken, amelyeket a Facebook és az Instagram évek óta képtelen kezelni a „hagyományos” módszerekkel. Ilyen például a gyűlöletbeszéd felismerésére használt tartalommoderációs algoritmusok fejlesztése és folyamatos trenírozása, vagy a kiterjesztett valóság beépítése egyre több közösségi funkcióba. És természetesen az RSC-t a Metaversum, a vállalat új “digitális valóságának” a fejlesztésére is felhasználják majd. “Az RSC segít a Meta AI kutatóinak új és jobb AI modelleket építeni, amelyek képesek billiónyi példából tanulni, több száz különböző nyelven dolgozni, zökkenőmentesen szöveget, képeket és videókat együtt elemezni, a kiterjesztett valósághoz kapcsolódó új eszközöket fejleszteni és még sok minden mást.” – írják a Meta mérnökei, Kevin Lee és Shubho Sengupta a híreket ismertető blogbejegyzésben.
Mit jelent mindez számunkra, tehát mit lát majd a fejlesztésekből az átlagfelhasználó? Egyrészt igen, a Meta továbbra is mindent megtesz, hogy egyrészt az utolsó cseppig kifacsarjon minden létező információt minden kommentből, kattintásból és a legapróbb interakciókból is – ez nem újdonság, a szolgáltatás a kezdetek óta ebből él. Viszont egy valóban jól működő szupergép segítségével talán tényleg megtörténhet, hogy ezeket az adatokat sokkal hatékonyabban elemzik és főleg védik is. Így amíg a bolygó egy része ész nélkül (igen, az NFT-kre célzunk) a decentralizáltság felé mozdul, addig a tech-óriások a valóságban továbbra is minden fontos szálat a saját kezükben tartanak, még ha ehhez minden eddiginél hatalmasabb gépszörnyeket is kell építeniük.








{kind=link}