

Sokat fejlődött a világ azóta, hogy papíralapú zsebszótárakban lapozgatva próbáltuk megértetni magunkat más nyelveket beszélőkkel. Ott viszont még mindig nem tartunk, hogy az általunk magyarul kimondott szöveg azonnal, helyesen és pontosan elhangozzon a partner felé egyfajta digitális szinkrontolmácsként. De vajon mikor jön el ennek az ideje?
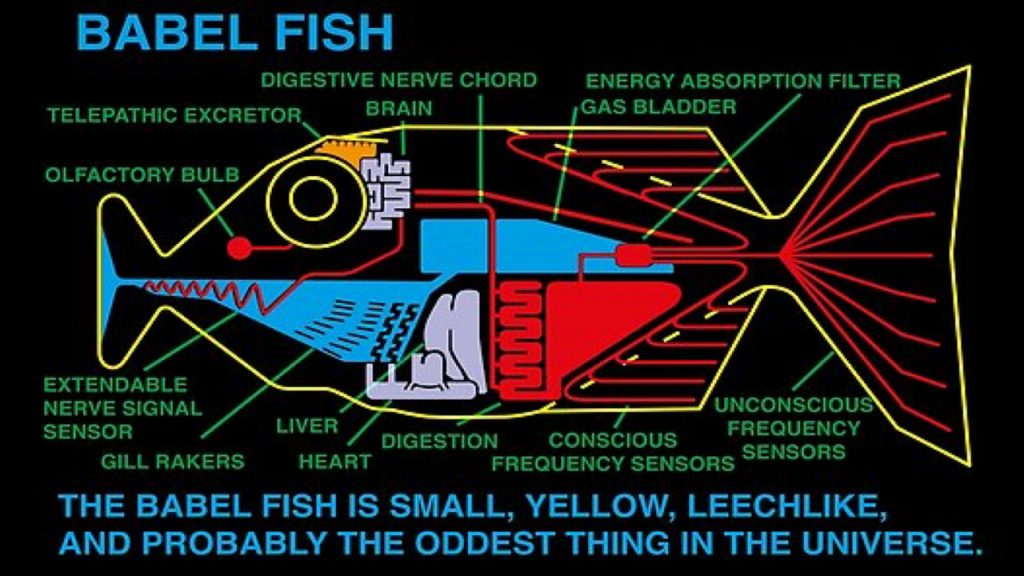
“A Bábel-hal […] kicsi, sárga és piócaalkatú, és valószínűleg a legfurcsább lény a világegyetemben. Agyhullám-energián él, mégpedig nem a hordozójáén, hanem azokon, amelyek kívülről érik a hordozóját. A beérkező agyhullám-energiák összes tudat alatti mentális frekvenciáját abszorbeálja, és testébe építi. Majd exkrementumként a hordozója agyába üríti azt a telepatikus mátrixot, amely a tudatos mentális frekvenciák és a hordozó elme beszédközpontja idegi jelzéseinek kombinálásából adódik. Mindez gyakorlatilag azt jelenti, hogy aki Bábel-halat dug a fülébe, az azonnal megért bárkit bármilyen nyelven. A ténylegesen hallott beszédelemek dekódolják azt az agyhullámmátrixot, amelyet a Bábel-hal táplál a hordozója agyába.”
A fenti idézet Douglas Adams talán legismertebb könyvéből, a Galaxis Útikalauz Stopposoknak című sci-fi őrületéből származik. Amikor ezt a könyvet először olvastam, még bőven a 80-as évek végén jártunk, és sokszor álmodoztam a Bábel-hal jelentőségéről akkor, amikor első külföldi útjaimon az angolon kívül bármilyen nyelv csupán kaotikus összevisszaságnak hangzott. De jó is lenne, ha a fülemben élősködne egy olyan apró lény, ami a fejembe továbbítja az elhangzott szöveg tökéletes fordítását, és persze lenne ilyenje mindenki másnak is, tehát innentől beszélhet mindenki az édes anyanyelvén, a világ többi része pedig a saját anyanyelvén érti majd, amit mondunk.
A szóról-szóra módszertől a mondatalkotásig
A papírszótárakat persze azért ma már felváltották szofisztikáltabb és jobban használható módszerek. Először a szószedet-alapú megoldások terjedtek el, amik a korábbi szótárakhoz hasonlóan annyit tettek lehetővé, hogy az általunk keresett szavakat bepötyögve kiadták azok egy vagy több jelentését. A bonyolultabb szövegek, tehát például ragozott formák, nyelvtani szerkezetek, kész mondatok megalkotása viszont még ekkor is a mi feladatunk volt.
A következő lépcsőfokot azok az online fordító szolgáltatások hozták, amelyek legismertebb képviselője minden bizonnyal a Google Fordító. Itt már elmozdulhatunk a szavaktól, és akár egy hosszabb, több bekezdésből álló szöveget is bemásolhatunk a bal oldali mezőbe, hogy aztán ezt egyben fordítsa az elérhető nyelvekre a szoftver. Sőt, a megjelenés óta sok funkció érkezett, az Androidot futtató telefonokon például egy csomó egyéb appba építve jelenik meg a lehetőség, hogy az adott alkalmazás elhagyása nélkül tudjunk szövegeket lefordítani. Szintén hasznos a kapott szövegeket kiejtő hangos mód, amelyet ugyan még teljesen szintetikus “robothang” mond, de már sokat segíthet abban, hogy az idegen nyelvek hangképzését is megtanulhassuk.
Hasonló szolgáltatások szép számmal bukkantak fel azóta is: az egyik legnagyobb meglepetést néhány éve a DeepL okozta, amely annak ellenére aratott komoly szakmai sikert, hogy a nagy techvállalatokkal szemben itt egy kisebb cég állt a fejlesztés mögött. A DeepL alapvetően nagyjából ugyanazt tudja, mint a Google szolgáltatása, de a próbák szerint a hosszabb szövegeket jóval érthetőbben, pontosabban és köznyelvibben tudja átültetni: a legfontosabb fejlesztési irány ugyanis a kontextus megértése.
Szóból is megárt a sok?
Bár természetesen a Google, a Microsoft és megannyi egyéb vállalat is dolgozik az ügyön, a fordító szolgáltatások jövője tényleg a kontextus, a szövegkörnyezet elemzésén és megértésén alapul. Nézzük csak a következő példát, ahol a Google Fordítóba az alábbi szöveget írtam: “Jó napot, a nevem Zoltán. Az ő neve Péter. Az övé pedig Zsuzsi.” Az angol változatban a következő eredményt kaptam: “Good day, my name is Zoltán. His name is Peter. And his is Zsuzsi.” Elsőre nem rossz, de nézzük csak meg jobban: a Zsuzsi előtt hímnemű névmás áll. Jó kérdés persze, kell-e tudnia egy fordító szoftvernek, hogy a magyar nevek közül melyik milyen nemet feltételez, de a ChatGPT és egyéb “infóturkász” megoldások korában szép lassan azt kell mondjuk: kéne.
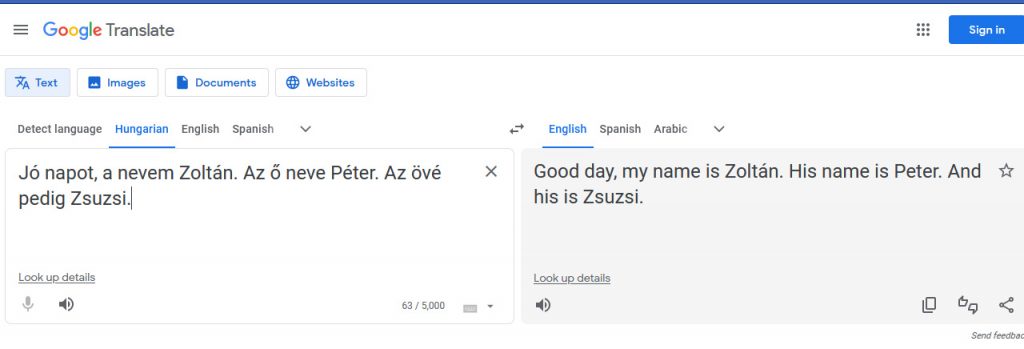
De nem csak erről van szó, mert a következő kísérletben kicseréltük a neveket angolra. Bill, Peter és Susan esetén a fenti mondatban szegény Susan még mindig hímnemű maradt, a szoftvernek egyszerűen kevés volt az, hogy “az övé pedig”. Ahogy kicseréltük az utolsó tőmondatot a kissé körülményesebb “Az ő neve pedig Susan” változatra, máris felvilágosult a gépagy, és javított her-re.
Mit mutat ez a rövid példa? Azt, hogy a jelenlegi fordító szoftvereket a legtöbb esetben még mindig az alapján toldozgatják, hogy a szavak egymás mellé rendeléséből rakják össze a lehető legjobb mondatokat. Egy hosszabb bekezdésben épp ezért már jóval kevesebb kohézió maradhat, egy sokadik mondatot a szoftver egyszerűen nem úgy érzékel, hogy annak köze van a szöveg elején leírtakhoz, hanem önmagában vizsgálja és fordítja. Ez alapján tehát elmondható, hogy írásbeli nyelvvizsgákat még mindig ne webes fordítószoftverek használatával akarjunk megúszni, ahogy hivatalos levelekbe se másoljuk be átnézés és nagyon gondos végigbogarászás nélkül az így generált szövegeket.
Az a bizonyos mesterséges intelligencia
Persze mostanában annyi szó esik az MI térnyeréséről, a ChatGPT jó és kevésbé jó oldaláról, hogy furcsa is lenne, ha a mesterséges intelligencia nem kapna szerepet a fent vázolt folyamat továbbvitelében. Mert azt már látjuk, mi hiányzik a mai fordítószoftverekből, és pont ez az, amit egy jól trenírozott, a teljes szöveg egészét megérteni igyekvő MI gatyába tud rázni.
Most meg is érkezett a hír az első olyan kísérletről, amely – legalábbis a fejlesztő állítása szerint – épp a teljes szöveg értelmezésére alapozva kínál MI-vel segített gépi tolmácsolást, méghozzá úgy, hogy teljes egészében hangról hangra dolgozik. Megérti tehát, amit mondanak neki, majd pedig szintén “élőszóban” adja vissza az idegennyelvű változatot. És ez a két dolog, tehát a kontextus-alapú működés és a szóbeli szinkrontolmácsolás kifejezetten komolynak hangzó lépés így együtt. Az Aivia nevű megoldás ugyanis képes arra, hogy eltárolja a “rövid távú memóriájában” azt, amit a beszélgető felek mondanak, és egy későbbi mondatnál egyeztetni tudja a szöveget a korábban elhangzottakkal, egyfajta folyományként, logikai sorként feldolgozva az információt.

Azt viszont még ne a napokban várjuk, hogy ingyenes webszolgáltatásként vagy app formájában használhassuk a svájci Interprefy megoldását. A zürichi cég ugyanis kifejezetten cégek, szervezetek számára kínál testreszabott módszereket az Aivia használatával, tehát külön ajánlatokat kell kérnie annak, aki szeretne a legmodernebb MI-tolmáccsal együttműködni. A cég eddig is üzleti konferenciák, távmegbeszélések, tárgyalások és előadások valós idejű fordítására fókuszált – többek között a Nemzetközi Űrállomáson az ő szoftvereik segítettek az asztronautákkal készült interjúk során, és a 2020-as labdarúgó EB sajtóeseményein is jól beváltak. Szerintük az MI felhasználása az egyértelmű új lépcsőfok, ami pont abban segít, hogy a beszélgető felek minden szempontból pontosan érthessék meg egymást. Az Aivia jelenleg is dolgozik üzleti modelljein, az viszont már látható, hogy az első körben 24 nyelv szerepel a kínálatában, és egy sor szoftverbe beépíthető a Teamstől a Zoomig.
Mit hoz a jövő?
Az egyelőre teljesen természetes fejlődési folyamat, hogy a legújabb, teljes komplexitásában szöveget értő tolmács-szoftvereket az üzleti szférára célozzák a fejlesztők. Azonban más újdonságok bevezetése alapján az is látható, hogy szép lassan megszületnek majd a konzumer megoldások is. Olyasmit lehet elképzelni, hogy egy telefon, vagy akár egy okosfülhallgató mikrofonjára érkező szövegeket egy mobilapp azonnal, vagy legalábbis pár másodperces csúszással tud lefordítani és szóban továbbküldeni a felhasználó fülébe. Az öntanuló, vagy épp felhasználók által tanítható modellek pedig azt vetítik előre, hogy az ilyen appok képesek lehetnek megtanulni a felhasználók nyelvhasználati sajátosságait, szlengjét, és akár hanghordozásból is tudnak majd extra információkat közölni (például különbséget tesznek majd a mérgesen, illetve pátoszosan elhangzó “az isten áldjon meg, fiam” változatai között, amik ugye két teljesen ellentétes dolgot jelenthetnek).
Azt persze szintén szem előtt kell tartani, hogy az MI-alapú megoldások kezdetben nem tökéletesek – ezt jól mutatja a ChatGPT fejlődése is. Épp ezért szinte biztos, hogy a szinkrontolmács appok által fordított mondatokat is kezdetben inkább irányadónak érdemes majd tekinteni, és az esetleges kétértelmű, vagy épp furcsán hangzó részletekre újra rákérdezni a partnereknél – egy diplomáciai tárgyaláson például konkrétan háborúk múlhatnak egy félrefordításon.
Arról pedig folyamatosan hallani, hogy a legnagyobb informatikai szereplők szinte mindegyike azon ügyködik, hogy MI-alapú megközelítéssel ruházza fel meglévő szolgáltatásait, tehát nem csodálkoznánk, ha hasonló képességekkel a Google, a Microsoft vagy az Apple is előrukkolna a közeljövőben. Addig pedig még mindig kell egy kis odafigyelés és pötyögés, ha olyan idegen nyelvvel kerülünk kapcsolatba, amihez külső segítségre van szükség. Kivéve természetesen, ha megtanuljuk az adott nyelvet, ami még mindig a leghatékonyabb megoldás.








{kind=link}